The voice of professional translators and interpreters around the world

FIT is the federation of professional associations of interpreters, translators and terminologists around the world, working in areas as diverse as literary, scientific and technical, public service, court and legal settings, conference interpreting, media and diplomatic fields and academia.
FIT supports members and the profession at an international level, building community, visibility and a sustainable future for the profession.
FIT Webinar:
The Translation Industry By Numbers: Between Growth, Transformation, and Reinvention

FIT (International Federation of Translators), in partnership with its Education and Continuous Professional Development Standing Committee, is holding a free live webinar on May 10th, 2024 at 1pm CET on the current state of the translation and interpreting market and the prospects for the future.
The webinar will be delivered by Gabriel Karandyšovský, a well-known industry researcher, consultant, and former COO of a global market research firm specialised in the translation industry.
Celebrating and Protecting the Art of Translation
International Translation Day 2024
Translation, an art worth protecting.
Inspired by issues surrounding copyright, this year’s International Translation Day (ITD) theme embraces the recognition of translations as original creative works in their own right, owed the benefit of copyright protection under the Berne Convention. As the creators of derivative works, translators have fought to protect their moral rights to be credited for their translation work, control any changes to that work, and receive appropriate remuneration. Protecting these simple things will ensure a sustainable future for translation professionals and the historic art of translation itself.
The Role of Indigenous Language Translation in the Midst of Climate Change: Negotiating displacement, loss of land, language and culture

On November 25, 2023, the FIT Indigenous Languages Standing Committee hosted a webinar titled The Role of Indigenous Language Translation in Midst of Climate Change: Negotiating Displacement, Loss of Land, Language and Culture.
Losing indigenous languages means a loss of cultural diversity, and the centuries-old knowledge contained within them, which could solve the current global challenges around climate destruction and biodiversity loss. Much of historical learning and knowledge about the planet is indigenous knowledge, therefore translation, interpreting and terminology for indigenous languages is key to unlocking that crucial knowledge.
Read the full article of watch the webinar on YouTube.
A new era of FIT

Despite the global challenges still facing us, 65 members were able to participate in the XXII FIT Statutory Congress in Varadero, Cuba on May 30th and 31st 2022, hosted by the Asociación Cubana de Traductores e Intérpretes (ACTI).
A new Council was elected, to lead FIT through to the next Congress in 2025. Meet the new FIT Council.
Barcelona Manifesto

On April 21, 2023, FIT joined the Association of Catalan Language Writers (AELC), the Council of European Associations of Literary Translators (CEATL) and hosts the Association of Professional Translators and Interpreters of Catalonia (APTIC) at the Gabriel García Márquez Library in Barcelona, in signing the Barcelona Manifesto on good contractual practices in translation for the publishing industry. Read the manifesto here.
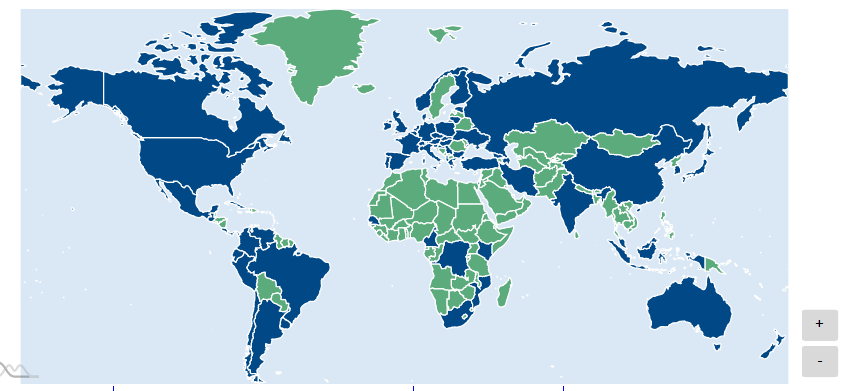
Our global reach